Published: Jan 21, 2020 by Dev-hwon
Unsupervised Learning (비지도학습)
- 데이터가 어떻게 구성되었는지를 알아내는 문제의 범주
- 지도 학습(Supervised Learning) 혹은 강화 학습(Reinforcement Learning)과는 달리 입력값에 대한 목표치가 주어지지 않는다.
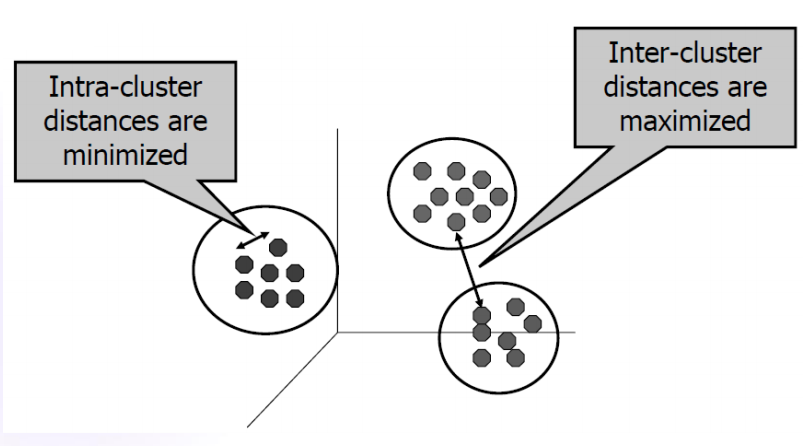
- 클러스터링: 같은 그룹 내의 객체 간의 거리는 작고, 서로 다른 그룹에 속한 객체 간 거리는 큰 그룹들을 찾는 것. 데이터의 분포를 보기 위함이나 다른 알고리즘으로의 전처리 과정으로 사용(예: 패턴인식, 이미치 처리, 문서 분류 등)
비지도학습 종류 별 간단 설명
자세한 설명은 따로 포스트할 예정
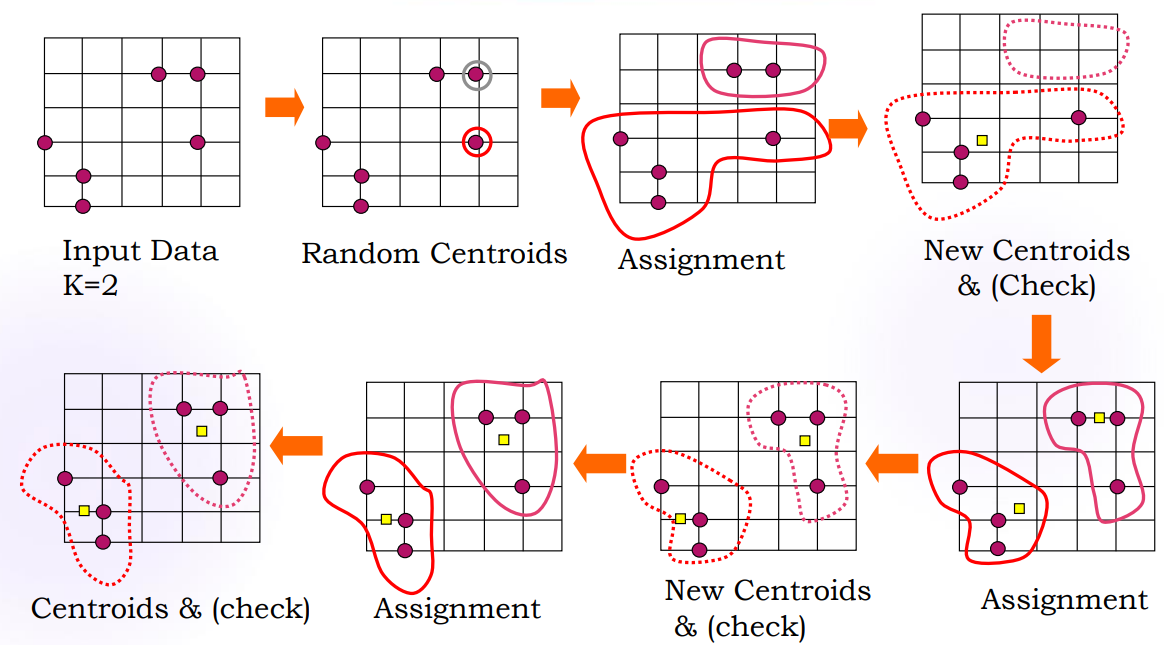
1. K-means
- k개의 군집의 중심 좌표를 기준으로 각 객체를 가까운 군집에 배정
1) k개의 중심 임의로 할당
2) 각 중심점에서 가까운 점들을 각 그룹으로 할당
3) 군집내의 모든 점으로 평균을 내어 새로운 그룹별 중심을 찾는다.
4) 새로운 중심에서 새로운 그룹으로 할당
5) 변화가 없을 때까지 2~4 반복
-
군내 변동이 작고 군간 변동이 클수록 성능이 좋다고 할 수 있다.
- 장점: 연산 시간이 적게 소요되고 대규모 자료의 군집화시 유용
- 단점: 군집의 수 k의 결정이 어렵고 이상값(노이즈) 민감
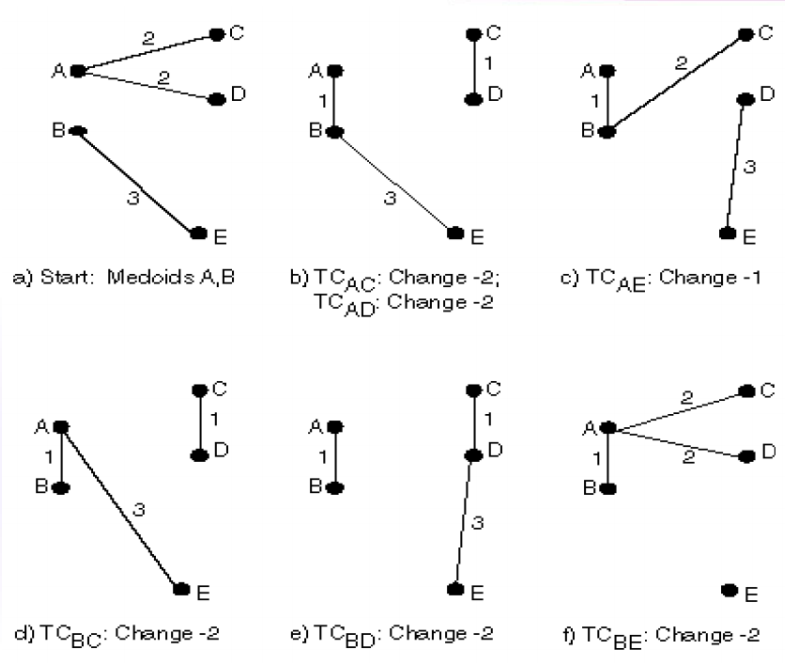
2. K-medoids
- 클러스터 내 중심에 위치한 객체를 이용
- k-means보다 이상치에 강하고 인풋의 순서에 영향을 받지 않음
- k-means보다 느림
- 하나의 클러스터가 하나의 객체로 대표될 수 있다는 특징
1) k개의 대표 객체를 임의로 선택
2) 남아있는 비대표 객체들을 가장 근접한 대표 객체가 속한 클러스터에 할당
3) 임의로 비대표 객체 h를 선택하여 각 대표 i에 대해 swapping cost 계산
4) swapping cost < 0 이라면 i 대신 h를 새로운 대표 객체로 설정
5) 변화가 없을 때까지 2~4 반복
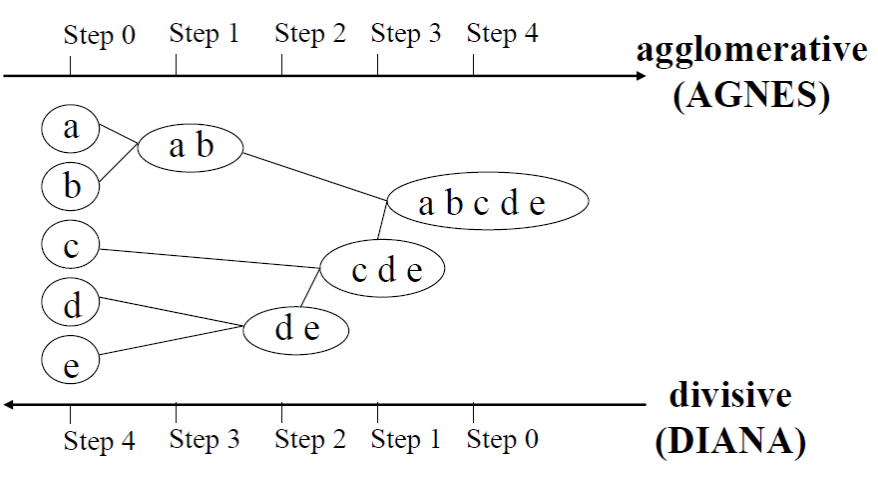
3. Hierarchical Clustering(계층 분석)
- 비슷한 군집끼리 묶어가면서 최종적으로는 하나의 케이스가 될 때까지 묶은 클러스터링 알고리즘
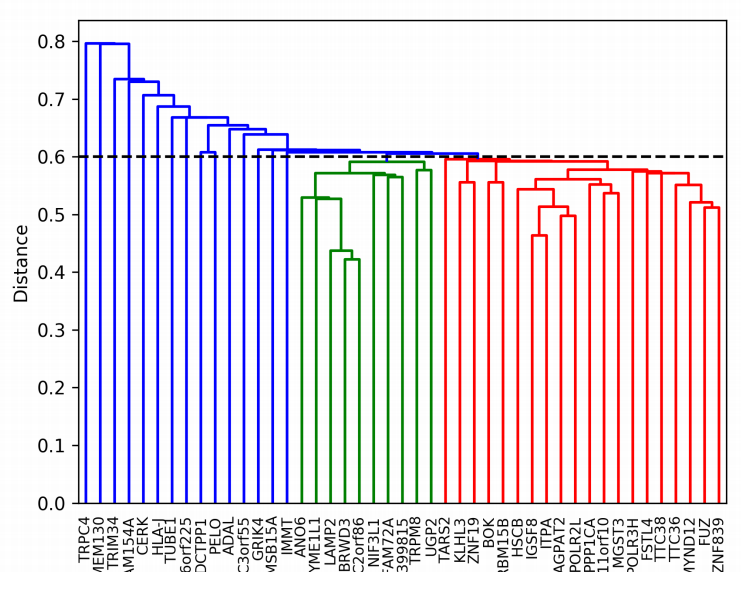
- agglomerative(AGNES)
- divisive(DIANA)